索引原理
B+树
B+树是谈到数据库/索引就绕不过去的话题,这里再复习下B+树的结构和特点。 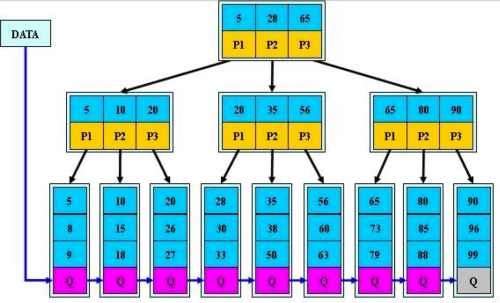
特点
- 从根节点到叶节点的所有路径都具有相同的长度
- 所有数据信息都存储在叶子节点,非叶子节点仅作为叶节点的索引存在
- 根节点至少拥有两个子树
- 每个树节点最多拥有M个子树
- 每个树节点(除了根节点)拥有至少M/2个子树
为什么在数据库中使用B+树
一直以来磁盘都是顺序读写的吞吐量远高于随机读写的吞吐量,即便现在固件硬盘不需要寻道了,这个特点仍然是存在的。 使用B+树的数据结构对于需要持久化存储的数据库来说仍然是最佳选择之一。
- B+树有高扇出性,在数据库中,B+树的高度一般不超过3层。这样减小了磁盘随机IO的次数
- B+树的各叶子节点用指针进行连接,每个叶子节点的大小一般为一个页的整数倍。 叶子节点用指针连接是为了尽量做到磁盘顺序IO,每个叶子节点的大小一般为一个页可以尽量利用操作系统的page cache机制
InnoDB中的索引
InnoDB中的索引可以分为两类:B+树索引和Hash索引。 Hash索引是自适应的,由引擎自动生成,无法人为干预,一般用在字典查找的情况下(比如根据字符串找主键id),所以这里就不介绍了。
B+树索引分为2种:Clustered Index和Secondary Index,它们的中文翻译有很多种,下面的文章中可能会混用这些中文翻译。
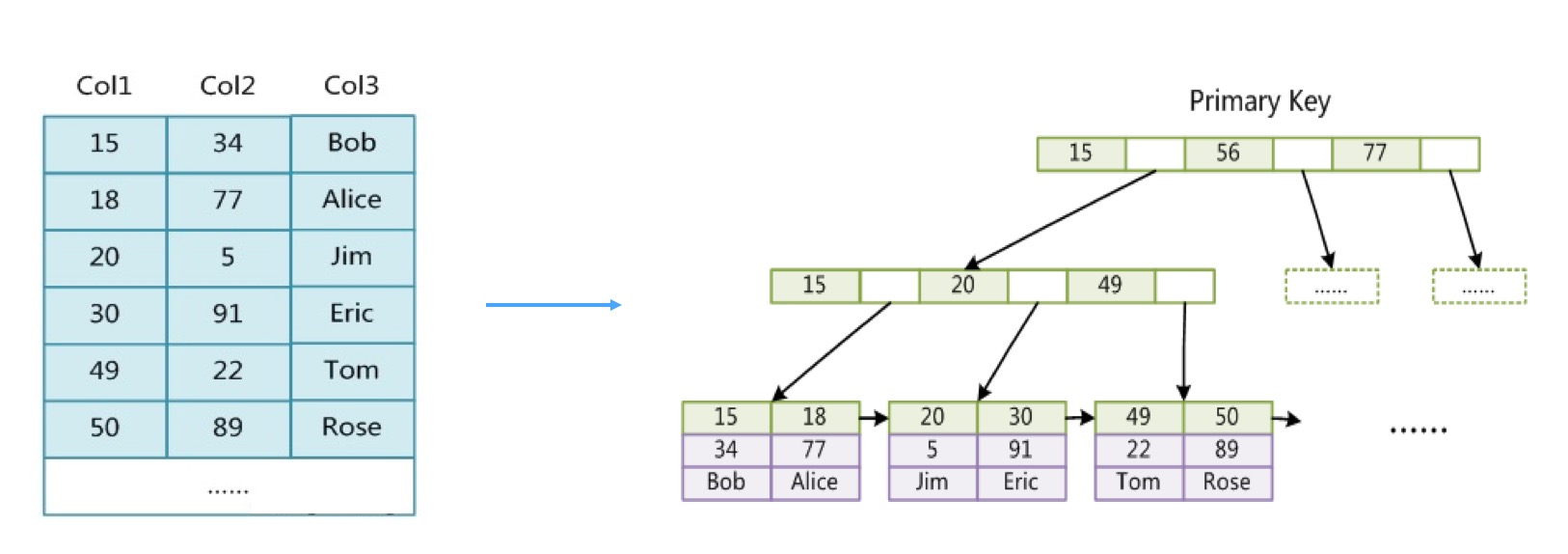
Clustered Index(聚簇索引/聚集索引/主键索引)
- 聚簇索引是以主键为关键字构造的一棵B+树
- 叶子节点存放整行记录的数据(也就是“聚簇”名称的由来)
- InnoDB中表数据文件就是主键索引文件。 这也是为什么InnoDB的表一定要有主键(不设置会默认生成一个),尽量不要用varchar作为主键、主键最好是自增/递增的也是同理。
Secondary Index(非聚簇索引/非聚集索引/辅助索引/二级索引)
- 以索引列构建的B+树
- 叶子节点仅存放对应记录的主键
单字段的二级索引(单列索引)
下面是一个单字段的二级索引的示意图,以一个varchar类型的列来建立。
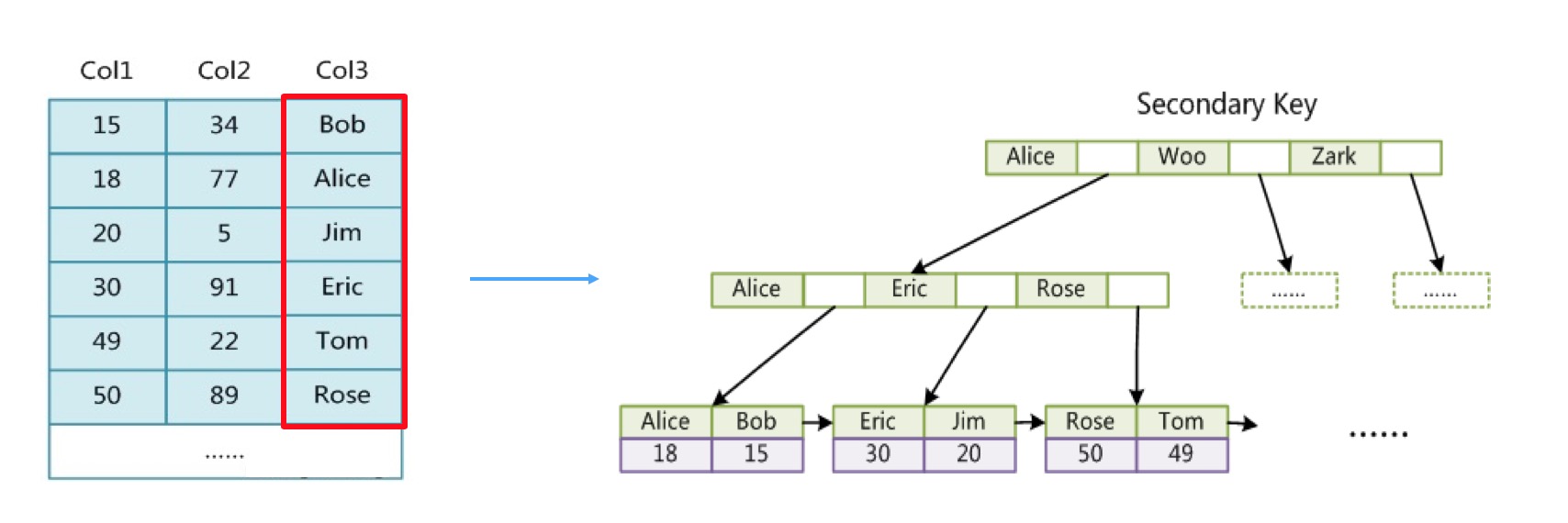
要注意varchar索引是按字母序排列的,所以如果想用上varchar类型的索引,LIKE查询时最左边不能有百分号%。
在Col3建立了索引的前提下,这样查询可以走索引: 1
SELECT * FROM a WHERE Col3 LIKE 'Er%';
1
2SELECT * FROM a WHERE Col3 LIKE '%Er';
SELECT * FROM a WHERE Col3 LIKE '%Er%';
多字段的二级索引(联合索引/多列索引)
下面是一个由多字段组成的索引的示意图,索引的顺序是先对第一个(最左边)字段排序,然后第二个、第三个… (单个字段的升序降序在创建索引时可以指定,默认都是升序)
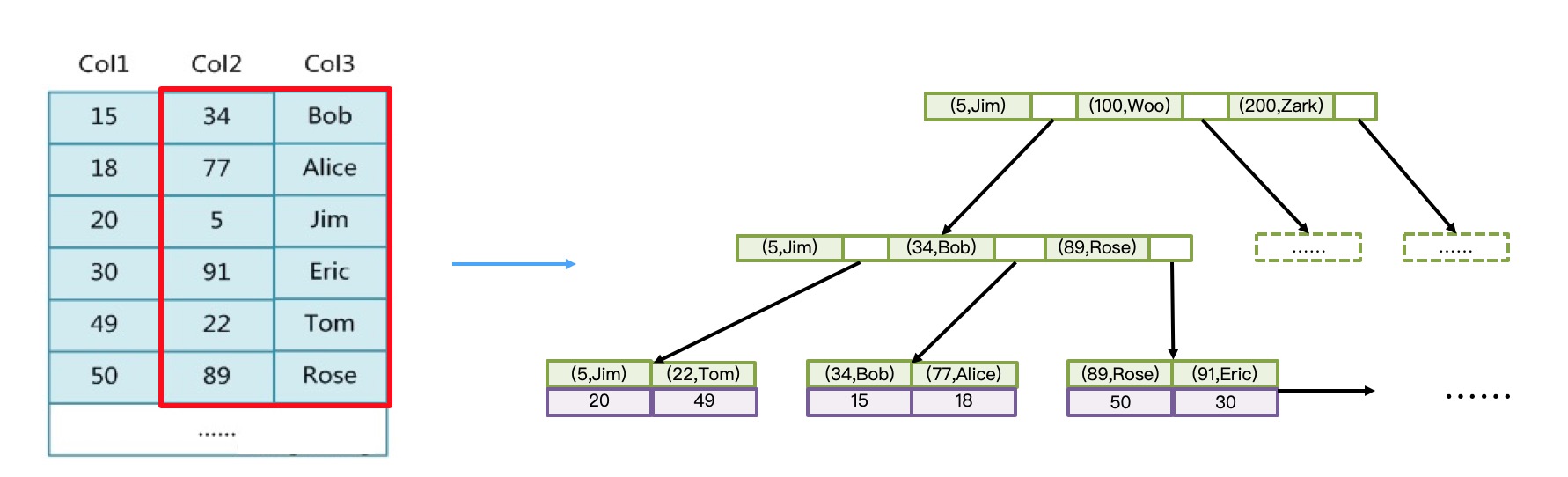
这里可以引出另外一个概念:如果SELECT的字段都在索引中,那就不需要回表了。这种情况称之为"covering index(覆盖索引/索引覆盖)"。 如下例: 1
SELECT Col2,Col3 FROM a WHERE Col2 = 5 AND Col3 = ‘Jim’;
这样引出了一个很重要的“最左前缀原则”:WHERE/JOIN等子句中的字段能匹配联合索引的某个“最左前缀”时才能用上索引。
对于上图中的示例,下面这个查询是可以利用上联合索引的: 1
SELECT Col2,Col3 FROM a WHERE Col2 = 77;
1
SELECT Col2,Col3 FROM a WHERE Col3 =‘Alice’;
索引选择性
所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数总数的比值。
在为某个字段建立索引之前,可以简单地通过DISTINCT来计算为它建立索引后的选择性: 1
SELECT COUNT(DISTINCT(title))/COUNT(*) AS Selectivity FROM a;
如果索引已经建立,也可以直接查看表的所有索引,查询结果中有Cardinality字段代表了不重复的索引值: 1
SHOW INDEX FROM a;
前缀索引
前缀索引应该是比较常用到的,对于varchat等类型的较长的列,用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
对于前缀索引同样可以预先计算其选择性,以便选取出最佳的前缀长度。 1
SELECT COUNT(DISTINCT(CONCAT(first_name, left(last_name, 4))))/COUNT(*) AS Selectivity FROM a;
小结
- 若查询条件中不包含索引的最左列,无法使用索引
- 对于范围查询,只能利用索引的最左列
- 对于order by A语句,在A上建立索引,可以避免排序
- 对于group by A语句,在A上建立索引,可以避免排序
- 对于多列排序,需要所有列(与索引中的)排序方向一致,才能利用索引
SQL代价估算
也可以理解成“SQL时间复杂度估算”,根据上面索引相关的内容,我们可以根据索引的情况来大致估算一个SQL的时间复杂度。
定义
SQL代价= Random IO(RO) + Sequence IO(SO) + CPU(内存计算)
- PK-Tree: 主键索引/聚集索引 的B+树
- SK-Tree: 二级索引/非聚集索引 的B+树
- h: B+树的高度
在B+树中查找一个key可以认为只需要从根节点到叶子节点“从上至下”进行一轮查找即可,可以简单地认为只需要遍历h个结点。因为这些父子节点在磁盘上一般不是连续存储的,所以认为是随机IO。因此代价是: RO(PK-Tree(h)) 。
而由于B+树叶子节点是相连的,遍历主键索引/二级索引可以认为是顺序IO,需要顺序遍历所有叶子结点(全表扫描)。因此代价是:SO(PK-Tree) 或 SO(SK-Tree) 。
例子
主键查询
1 | SELECT … FROM table WHERE primary_key = ? |
根据主键查询,只需要在主键索引中进行查找即可。
代价: 1
RO(PK-Tree(h))
列查询(无索引)
1 | SELECT … FROM table WHERE col = ? |
查找没有索引的列,需要对主键索引进行一次全表扫描。
代价: 1
SO(PK-Tree)
列查询(有索引)
索引:index(key) 1
SELECT … FROM table WHERE key = ?
代价: 1
RO(SK-Tree(h)) + N*RO(PK-Tree(h))
二级索引扫描(索引覆盖)
索引:index(col_A,col_B) 1
SELECT col_A, col_B FROM table
代价: 1
SO(SK-Tree)
列排序(无索引)
1 | SELECT * FROM table WHERE col_A > ? ORDER BY col_A |
代价: 1
SO(PK-Tree) + CPU运算
列排序(有索引)
索引:index(col_A) 1
SELECT * FROM table WHERE col_A > ? ORDER BY col_A
代价: 1
SO(SK-Tree) + N*RO(PK-Tree(h))
连接查询(无索引)
1 | SELECT … FROM t1 JOIN ON t2 WHERE t1.name = t2.name |
代价: 1
SO(t1-PK-Tree) * SO(t2-PK-Tree)
连接查询(有索引)
索引:index(t2.name) 1
SELECT … FROM t1 JOIN ON t2 WHERE t1.name = t2.name
1
SO(t1-PK-Tree) * RO(t2-SK-Tree(h))
小结
- 主键查询优先于二级索引查询
- 单表查询优先于连接查询
- 表连接数量越少越好
- 二级索引扫描优先于全表扫描
- 使用通过索引避免排序代价
锁机制简述
锁机制不是本文的重点,但这里也提一下常见的死锁问题的原因及对SQL写法的建议。
InnoDB的事务隔离级别
老生常谈了,直接放图。
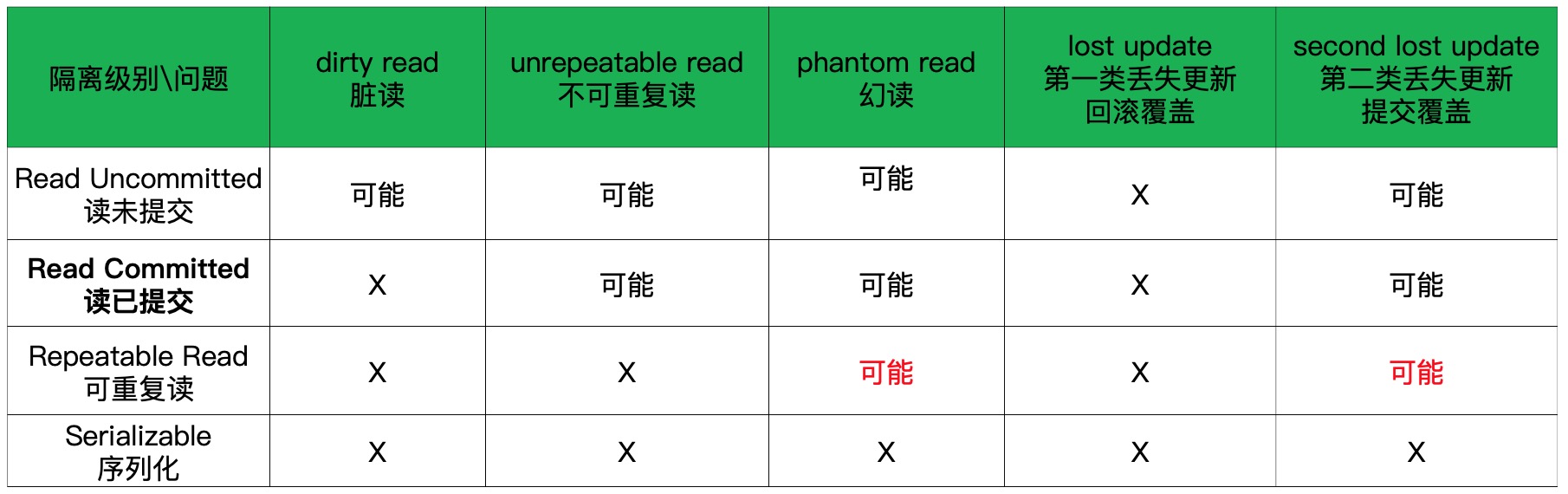
- RR级别下仍然有可能出现提交覆盖,可使用SELECT FOR UPDATE或版本号列(乐观锁)解决
- RR级别下有Next-Key/Gap锁,SELECT可通过加锁(FOR UPDATE/LOCK IN SHARE MODE)来避免幻读
InnoDB中的锁
1 | SELECT * FROM information_schema.INNODB_LOCKS; |
通过该SQL可以查询当前出现的锁。(另外还有INNODB_TRX记录当前事务,INNODB_LOCK_WAITS记录锁等待关系)
按 锁类型(lock_type) 分
锁类型描述的锁的粒度,也可以说是把锁具体加在什么地方。
按锁类型可以分为 表锁 和 行锁,行锁又分为4类:
- Next-Key Lock,锁一条记录及其之前的间隙,这是 RR 隔离级别用的最多的锁
- Gap Locks:间隙锁,锁两个记录之间的 GAP,防止记录插入
- Record Locks:记录锁,只锁记录
- Insert Intention Locks:插入意向 GAP 锁,插入记录时使用,是 Gap锁的一种特例
按 锁模式(lock_mode) 分
锁模式描述的是到底加的是什么锁,譬如读锁或写锁。
在表级别下有2种:
- IS:读意向锁
- IX:写意向锁
在行级别下有3种:
- S:读锁
- X:写锁
- AUTO_INC:自增锁
加锁机制
下面看下各种情况下InnoDB的加锁机制,注意这里只讨论Read Committed隔离级别下的情况。
主键索引加锁
id为主键,隔离级别:Read Committed 1
DELETE FROM t1 WHERE id = 10;
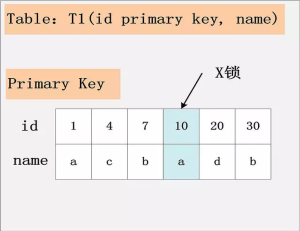
- 只有id=10这行加上了X锁
二级索引及主键索引加锁
id为普通索引,隔离级别:Read Committed 1
DELETE FROM t1 WHERE id = 10;
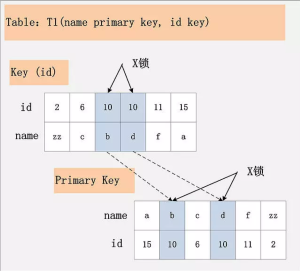
- id这个二级索引上的所有id=10索引记录加上X锁
- 主键索引上的对应记录加X锁
唯一索引及主键索引加锁
id为唯一索引,隔离级别:Read Committed 1
DELETE FROM t1 WHERE id = 10;
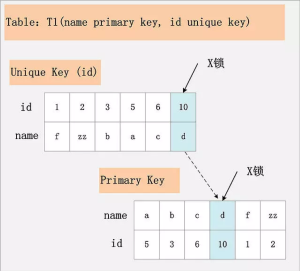
唯一索引也是一种二级索引,不过有唯一约束,所以跟上例相比区别是只锁了一条记录。
- id索引上的id=10索引记录加上X锁
- 主键索引上的对应记录加X锁
主键索引全表加锁
id无索引,隔离级别:Read Committed 1
DELETE FROM t1 WHERE id = 10;
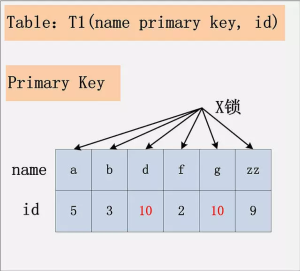
- 主键索引上的所有记录加X锁
死锁的情况
常规情况
最常见的情况,就像线程死锁一样,两个或多个事务进入了互相等待锁的情况。

二级索引造成的死锁
索引:idx_1(user_id, item_id, status)

假设两条语句实际要修改的是同一条记录:
- 第1条语句先获取了idx_1的X锁,再尝试获取主键索引的X锁。
- 第2条语句先获取了主键索引的X锁,再尝试获取idx_1的X锁。
这样就造成了死锁。
小结
- 同一张表的DML语句中的WHERE条件尽量保持一致
优化建议
SQL优化
- 建议读写都采用主键索引
- 尽量避免使用select
- 尽量利用索引排序,避免产生临时表
- 避免对查询字段进行计算(类型转换,计算)
- 避免在查询中对查询字段使用函数
- 避免索引列有NULL值,索引失效(is null,is not null)
- 如果条件中有or,即使其中有条件带索引也不会使用,要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- 避免隐式类型转换
- 避免使用全模糊查询 like '%xxx%’
应用级别优化
何时该分库分表
- 单表数据量超过500w时
- 数据容量超过10G时
这里指的“一般情况下”,如果表比较复杂那么应该提前考虑,如果表结构简单则反之。
应用缓存
- 读远高于写的情况
- 可以接受短暂数据不一致时可以使用本地缓存
- 需要强一致性时使用redis等缓存
关于连接池
连接池这里不赘述,如果有事务中有RPC调用,可能会导致连接池耗尽,这个时候可能需要调整连接池参数,但需要谨慎。
什么情况下会耗尽
- 慢SQL过多
- 事务耗时过长/死锁
- 尽量不要在事务中进行RPC调用
实战
case1: 多列的排序方向需(与索引定义的)一致
这个是从某应用的慢SQL,SQL简化如下:
1 | SELECT `a`.`id`, `a`.`gmt_create` ... |
有2个索引,explain显示这个查询走了idx_2:
1 | idx_1 (biz_type,version_date) |
通过EXPLAIN看也是走了idx_2,但索引中的sc_item_id、store_code字段都是升序的,都改成升序后查询速度能有一定的提升:
1 | ORDER BY `a`.`sc_item_id` ASC, `a`.`store_code` ASC |
case2: 注意索引有效性/及时删除无用索引
还是从某应用慢SQL里面提取出来的,SQL简化如下:
1 | SELECT `b`.`id`, `b`.`gmt_create`, `b`.`gmt_modified`, `b`.`biz_type` ... |
有2个索引,explain显示这个查询走了idx_1:
1 | idx_1 (biz_type,version_date,rel_code,rel_type,row_status) |
这个就比较奇怪了,idx_1按最左前缀原则只能匹配上前2个字段(biz_type,version_date),idx_2却能匹配上WHERE+ORDER的全部5个字段,为什么还要走idx_1? 虽然在idx_2中gmt_modified是升序的,但只有一个ORDER BY字段应该还是能利用上索引的呀。
分析索引
先通过SHOW INDEX来查看索引: 1
SHOW INDEX FROM `b`;
是不是因为Cardinality的原因SQL优化器认为走idx_1是更优的?
指定索引试试
可以通过USE INDEX来指定索引:
1 | SELECT `b`.`id`, `b`.`gmt_create`, `b`.`gmt_modified`, `b`.`biz_type` ... |
实际测试下来查询速度有30%左右的提升,这提示我们:
- SQL优化器不一定能选择出最优的索引
- 经常分析慢SQL与索引,尽量删除无用的索引
case3: 查询字段避免使用函数
这个case比较简单,在查询字段上进行计算或者使用函数都会导致走不了索引:
1 | SELECT * FROM a WHERE uid= 48123 AND (TO_DAYS(now())-TO_DAYS(biz_time)<= 90 OR biz_time IS NULL) AND is_deleted= 0; |
可以在应用中先计算出对应的日期作为参数:
1 | SELECT * FROM a WHERE uid= 48123 AND (biz_time>=‘2019-05-18’ OR biz_time IS NULL) AND is_deleted= 0; |
case4:分页查询延迟关联
索引:index(end_time)
1 | SELECT id, name, biz_type, end_time, market_type FROM relation WHERE biz_type = ‘0’ AND end_time >= ‘2018-05-29’ ORDER BY id ASC LIMIT 150000, 20; |
MySQL 执行此类sql时需要先扫描到N行,然后再去取 M行。对于此类大数据量的排序操作,取前面少数几行数据会很快,但是越靠后,sql的性能就会越差,因为N越大,MySQL 需要扫描不需要的数据然后在丢掉,这样耗费大量的时间。
可以进行如下优化:
1 | SELECT a.id, a.name, a.biz_type, a.end_time, a.market_type FROM relation a, |
参考文档
- MySQL索引背后的数据结构及算法原理
- mysql 索引加锁分析
- 解决死锁之路 - 了解常见的锁类型
- 《MySQL技术内幕-InnoDB存储引擎》